
A New Optimization Approach for Parkinson’s Diagnosis
Tarih: Date -
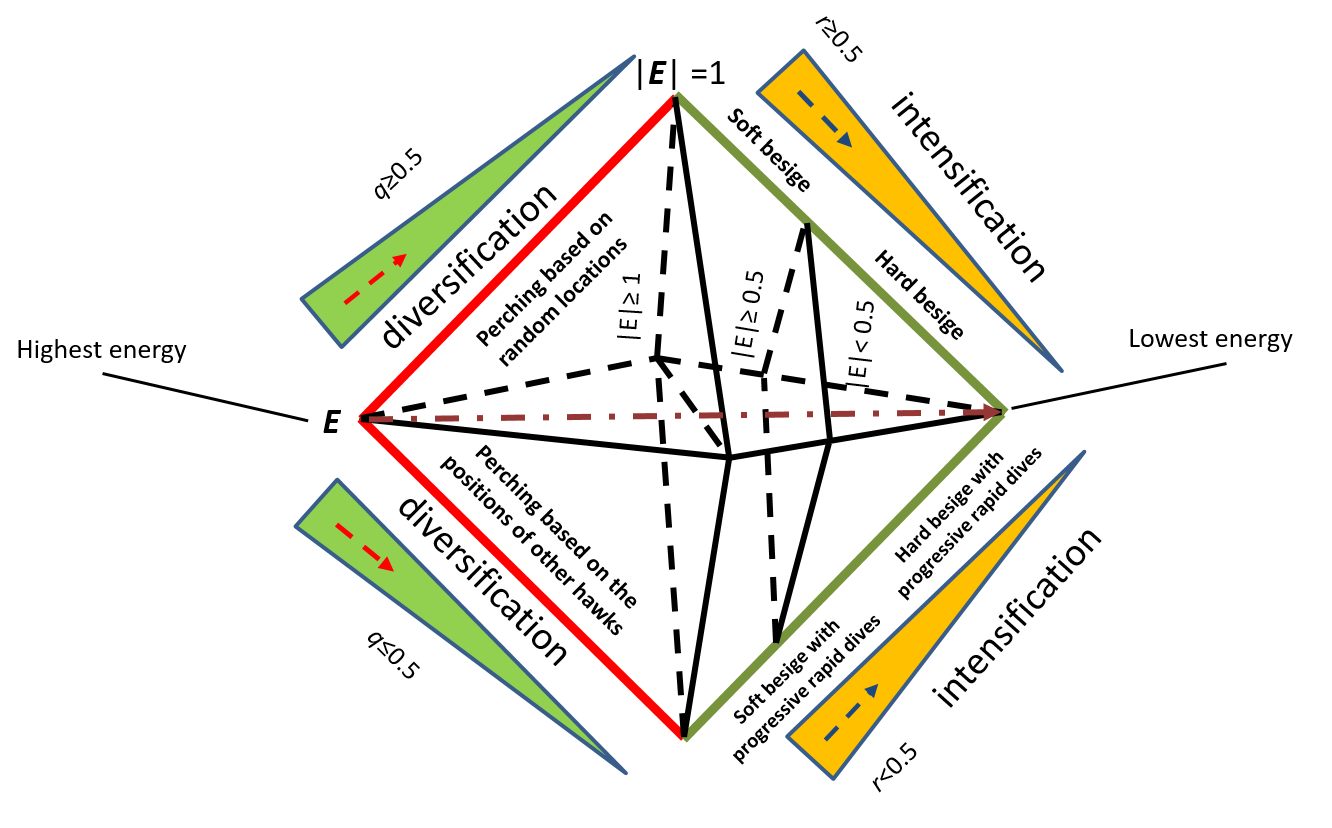
A new study led by Prof. Dr. Tansel Dökeroğlu, Director of the Department of Software Engineering at TED University, introduces an innovative method to improve feature selection in the computer-aided diagnosis of Parkinson’s disease. The proposed binary Multi-objective Harris Hawk Optimization (MHHO) algorithm is integrated with an adaptive K-Nearest Neighbor (KNN) classifier, offering high accuracy and efficiency.
To reduce computational time in large-scale datasets, the study also presents a parallel implementation based on the Message Passing Interface (MPI). The MHHO algorithm has been extensively compared with commonly used techniques in the literature, such as Genetic Algorithm, Particle Swarm Optimization, and Cuckoo Search, and has demonstrated superior results in most datasets. Moreover, the proposed method achieves over 30% reduction in the total number of features across all datasets, significantly lowering computational costs.
The abstract of the article is provided below:
Parkinson’s disease, an idiopathic neurological illness, affects over 1% of the global elderly population. Feature-based methods are frequently used to diagnose Parkinson’s disease, and selecting the best feature set remains an ongoing and difficult challenge. In this study, we introduce a new binary Multi-objective Harris Hawk Optimization (MHHO) algorithm that combines an adaptive K-Nearest Neighbor (KNN) classifier with novel exploration and exploitation operators for this challenging task. In larger problem instances, where fitness evaluation is a bottleneck, this study proposes a parallel version of the technique that uses Message Passing Interfaces (MPI) to reduce computational complexity. Comprehensive comparisons with state-of-the-art algorithms, including Genetic Algorithm, Particle Swarm Optimization, Binary Bat, Cuckoo Search, and Grey Wolf Optimization, are performed. The results indicate that our proposed algorithms are consistently the most successful in the literature. Furthermore, our analysis provides new optimal solutions that have not previously been reported in the literature. For three of the four well-known datasets, our algorithm outperforms recent studies. Furthermore, the suggested approaches achieve more than 30% reduction in the total number of features across all datasets, thereby significantly lowering computational costs.
You can access the full text of the article via the following link: ScienceDirect